Research proposal
Échanges de
connaissance structurée médiatisés par ordinateur
Computer-mediated exchange of structured knowledge
![[EXMO]](../img/exmo-small.gif)
INRIA Rhône-Alpes
December 1st, 1999
Research proposal
This proposal aims at providing indication and motivations for our research directions in the next few years.
Exmo promotes the use of formalised knowledge in computer mediated communication between people. The knowledge can be used by both computers and people. As starting assumption is the belief that formally expressed knowledge accessible to computers is a the ground for many innovative applications. In the communication process, the computer can add value to its medium and memory functions by performing advanced functions such as formatting, filtering, categorising, consistency checking, or generalising.
This view can readily be implemented in technical memories or scientific knowledge bases, and will spread to all the aspects of information systems in the future (especially in the context of the generalisation of computer supported collaborative work).
Figure 1 displays the knowledge flow in an organisation involving human and software agents. These agents can be both producers and consumers of knowledge represented in the computer. The organisation itself can be considered as such an agent.
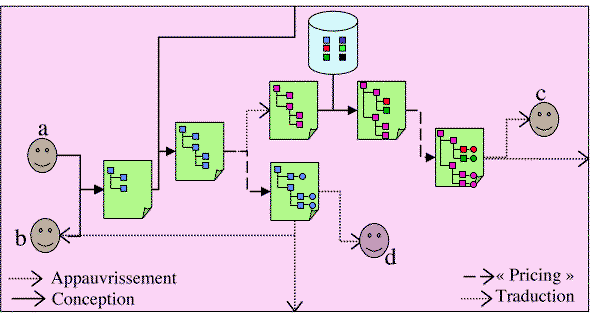
Figure 1 : Knowledge flow and transformation within the organisation.
More concretely, agents (a) and (b) collaborate to the design (C) of a document (or a knowledge base, or a design model) about some product. An external source (e.g. an administration) provide more knowledge (e.g. about reglementation) which is aggregated in the previous document. Depending on the commercial channels, this information can be translated (T) into another languages, completed (P) by the pricing information or formatted (A) to various destinations (included external ones). This kind of organisation is by no way futuristic: it is already at work in concurent engineering, electronic document management, or knowledge management.
The Exmo activity aims at investigating the rules involved in such organisations. To that extent, the various stages of Figure 1 are considered as knowledge bases and the transitions are considered as transformations (which can be the combination of several knowledge bases). Paying attention to formalised knowledge allows to go beyond document management by considering both the structure and the meaning of the transformed objects.
One focus point in the Exmo research, is the properties satisfied by transformations and preserved by the composition of transformations. Such properties can aim at preserving or hiding the structure or meaning of knowledge base (e.g., natural language translation should preserve the structure and meaning).
For instance, it can be useful to define a transformation which delivers a
documentation to a costumer but which hides some information from the
initial source (e.g., if a design document includes cost study, it is not
advised to communicate this information to sub-contractors). In the context
of collaborative work, it is useful to establish the properties of such a
filter in order to know where to implement it in the organisation.
Conversely, when the elaboration of a representation is a collaborative
and continuous process (in the concurent engineering framework), it is
necessary to apply treatments which do not
challenge inadequately the current stage of developpement. It is thus
relevant to warrant the preservation of content.
The Exmo challenge is the development of theoretical and computer tools for helping the organisation, manipulation, presentation and combination of structured knowledge chunks while allowing communication between people. It requires to developp an abstract understanding of representations and the transformations applied to them.
We aims at contributing in two research directions called transformation and communication. These direction takes advantage of the knowledge representation aspect.
The Exmo research work aims at generalising away from particular representation languages. However, in order to frame the scope of investigations, it is bounded by two representation languages:
Our previous work on the exchange of formalised knowledge is continued and particularly its communication through the worldwide web and its contribution to the web. Concerning this last point, a cooperative research action for comparing the efficiency of three knowledge representation languages (conceptual graphs, object-based representations and description logics) for indexing documents by content.
A transformation*
is a computational way of generating one or several
representations from one or several other representations (not necessarily
written in the same formal language).
The goal of the transformation topic
is the elaboration of a "general theory of transformations" based on the
properties that transformation satisfies (rather than on the
representations or the transformation themselves).
One outcome of this work is the capability to decide, given an organisation such as that of Figure 1, composing several transformations, and the properties of these transformations, the properties satisfied by a particular output of the organisation. This should be a precious tool for the future information system architects.
More generaly, one goal could be, given a set of transformation types
and a set of transformation composition operators -- let this be called a
transformation system --, to establish if a property can be decided for an
instance of the transformation system (and to provide a way to decide it).
We are interested by the properties satisfied by tranformations. Such properties
include content or structure preservation, source traceability, or conversely,
confidentiality. The goal of Exmo is not to help the implementation
of transformations or to infer properties from implementations. However,
some (generally simple) transformation languages implements only one
specific interaction type (e.g. filter) and thus our work is connected to
transformation languages in that way.
One of the first key point that are developped is the classification
of transformations with regard to an order between representations (e.g.
"containing more information than" or "having a tree structure completing
that of"). For each order, four properties can be defined
depending on the precedence of a representation over its
transformation and/or the precedence of the transformation over the initial
representation.
For instance, in Figure 1 two type of transformations have been
distinguished depending on the preservation of information (strenghthening)
or its non-preservation (weakening). Many such classifications can affect
transformations.
This last example introduces a separation between two kind of work developped before: strenghtening and weakening of representations (considering that the represented situation remain the same). These two properties are related to meaning preservations and its reverse.
Strengthening accounts for:
In a dual way, generally automatic, weakening generates a more abstract representation than the initial one. These new representations will have to preserve specific properties of the initial representations. These properties can be related to:
Both aspects can be articulated in the following figure:
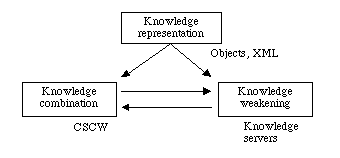
How to ensure the understanding of the knowledge between two people? Formal semantics developped for knowledge representation systems is suited to the use of a system by one user because it is expected that (s)he interprets in a coherent way the terms (identifiers) used. However, when several users communicate, this understanding becomes problematic. Work developped in the field of consensual ontology construction could help to solve the problem of term interpretation.
However, other problems are involved. For instance, a user can express
knowledge under the form of class hierarchies and first order clauses and
then communicate it by using an interoperability language. But if this last
language expresses the whole knowledge with clauses (though preserving the
semantics of the assertions), the initial user will hardly recognise (and
hardly understand) the semantically equivalent result.
Hence, when a transformation operates a translation between formal
languages, well understanding cannot be ensured by meaning preservation. A
semiotic (or pragmatic as it is called in linguistics) treatment must be
applied for ensuring the meaning reconstruction. This treatment comes as a
complement to the sheer semantic treatment used in the knowledge
representation area.
In order to contribute to the solution of this last problem, we investigate the embedding of communicating the semantics together with the syntax of the language used. Consequently, the translation into an interoperability language is not required. Thus, the form can be preserved as much as possible (form is relevant to human understanding) and interoperability is ensured through the availability of the semantics (correct computer treatment mainly depends on semantics).
One step further on this line leads to the consideration, together with structure and semantics, of the interpretation of signs. This is a key topic of computational semiotics.
The two threads developped above can be merged in a common goal: that of developping a computationnal semiotics, i.e. an understanding of sign systems and their interpretations exploitable by computers. This theoretical and prospective thread aims at exploring, in the most abstract way, how various representations, that may be expressed in different languages, can be related. If one considers that these representations are used both for mediating communication between people and supporting computer-based manipulations, the sign systems they constitutes for the users have to be taken into account. Since it is hardly possible, for a computer, to assess the meaning of the representation, the way to reconstruct it must be embedded in the representations and the computer must take care of it during its manipulations. This is more specifically related with:
Troeps knowledge servers enable the use of Troeps as a HTTP server instead of a knowledge base system. Then, anyone can browse and edit the knowledge base with the help of a HTTP client. This knowledge is also linked to informal text, pictures, a lexicon and other web sites. [o] is a review of related projects worldwide.
Knowledge bases can be used as Web servers whose skeleton is the structure of formal knowledge (mainly in the object-based formalism) and whose flesh consists of pieces of texts and images tied to the objects (see [Euzenat1996a]). The advantages of such an approach are found in the consistency of the base (there are no dangling link since the skeleton is generated automatically) and the opportunity to build complex queries grounded on the formal knowledge. This combines the advantages of a very structured server with the freedom of usual servers. It participates in the Knowledge medium * idea and can be called an "intelligence added" web server. A server on the fruit fly (D. melanogaster) genome has been built [Euzenat&1997a].
The Troeps knowledge servers allow the user to create, modify or destroy the objects and the conceptual scheme of the knowledge base. Editing raises problems of consistency and concurent access to the base. This is the subject of the application to Collaborative work.
This technological thread aims at developping and investingating support for:
Co4 is an environnement enabling a group of geographically distributed users to build together a knowledge base accessible through the worldwide web. The collaboration between users is managed by a protocol which warrants that common knowledge bases are consistent and consensual. The protocol is implemented as library that can be used for other applications which aim is the collaborative construction of an artefact. This has been applied to scientific knowledge base construction (in genomics) and corporate memories (in micro-electronics).
| EXMO : research | people | papers | teaching | training | cooperation | software | applications | transfert | | © | ? | * |
| http://exmo.inria.fr/research/initprop.en.html | © INRIA, 1999-2000 |