Action ESCRIRE
Méthodologie de comparaison
jeudi 9 mars 2000
Introduction
Afin de manipuler efficacement une base de documents (par exemple un site web), on cherche à indexer les documents par leur contenu (ou leur sens). Cela permet de rechercher les documents pertinents en utilisant des requêtes structurées tirant parti des formalismes de représentation de connaissance actuels (hiérarchies de classes, mécanismes de classification...). Pour cela, une représentation du contenu dans un formalisme de représentation de connaissance par objets devra être intégrée dans le document. Mais laquelle ? Afin d’avoir une idée plus précise de l’adéquation des formalismes de représentation de connaissance à cette tâche, l’action ESCRIRE a pour but de comparer trois formalismes : graphes conceptuels, représentation par objets et logiques de descriptions. Le présent document fixe la méthodologie de comparaison mise en œuvre.
Méthodologie
Données
Il est prévu d’utiliser deux jeux de données (très similaires) dont l’un sert à l’entraînement des logiciels et l’autre à leur évaluation (il serait encore plus utile de disposer de trois jeux : entraînement, premier test, évaluation).
Par jeu de données on entendra :
Les documents et requêtes concerneront un même domaine qui sera modélisée dans la représentation pivot par l’ensemble des participants (modèle commun aux deux jeux de test).
Les données seront des " méta-données " introduites dans un document. Elles se composeront donc de trois parties :
Pour des raisons de simplicité du processus, le champ contenu ne contiendra pas de référence aux autres documents mais pourra faire référence à l’" ontologie ".
Processus
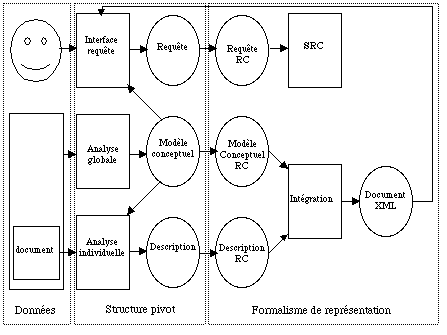
Le processus mis en œuvre est présenté dans la deux figure suivante :
Il nécessite l’encodage du contenu des documents à partir d’une représentation pivot (qui pourrait être celle engendrée à partir d’un mécanisme de traitement automatique de la langue naturelle, mais qui dans notre cadre sera engendré manuellement). De même, les requêtes devront être traduites à partir d’une représentation pivot. Ainsi, les formalismes comparés sont placés sur un réel pied d’égalité (les mêmes représentations et requêtes entrent en jeu au lieu d’être exprimées dans des langages différents).
Logiciels comparés
Le but de l’expérimentation est de comparer trois logiciels utilisant des systèmes de représentation de connaissance différents (GC=graphes conceptuels, RCO=représentation de connaissance par objets, LD=logique de description). Afin d’avoir un témoin extérieur aux performances de ces systèmes, on les comparera avec les performances d’un logiciel de recherche texte intégral (TI).
Pour que les mesures soient objectives, il est nécessaire que les entrées/sorties des logiciels soient les mêmes, d’où l’utilisation d’une structure pivot. Cependant, afin de prendre en compte le biais introduit par cette structure vis-à-vis des logiciels, il sera permis aux équipes qui le désirent de procéder à une seconde vague de test avec un encodage manuel des données d’entrée (respectivement mGC, mRCO et mLD).
Mesures objectives et subjectives
Il est souhaitable que la plupart des tests puissent se faire de manière automatique.
Il n’est pas interdit, cependant d’introduire des tests manuels avec un critère d’évaluation subjectif (voir plus bas). On aura alors deux types de test qualifiés dans le document Concerto de " test externes " et de " qualité à l’usage (quality in use) ". En tout état de cause, le développement d’évaluation subjective nécessite de décrire l’ensemble du contexte d’évaluation (caractéristiques de l’utilisateur, de la tâche, de l’environnement).
Il n’est cependant pas souhaitable que puissent intervenir une manipulation des structures de représentation par l’utilisateur dans ces tests subjectifs. Dans un second temps, il peut être intéressant de définir un second ensemble de test subjectif avec manipulation directe (création de requête dans le langage de représentation par exemple). Cependant, hors d’un protocole extrêmement contrôlé, ces tests ne pourront pas être considérés comme significatifs.
Critères
Définition des critères objectifs
Rappel : % de réponses à une requête par rapport aux réponses attendues ;
Précision : % de réponses attendues par rapport aux réponses données ;
Performance : temps utilisé pour répondre à une requête. Afin d’avoir une idée expérimentale intéressante de cette grandeur (et sachant que les logiciels utilisés sont des prototypes de recherche non optimisés), il est nécessaire de l’évaluer dans le contexte de bases avec des ordres de grandeurs différents (pour la même requête) et de requêtes avec des complexités différentes (pour la même base).
Pertinence de l’ordre : Il est nécessaire de définir un degré d’accord de l’ordre des réponses retournées avec l’ordre escompté (pas facile) ;
Couverture des types de requêtes
Agrégation
Il sera sans doute nécessaire de définir des agrégations des mesures brutes données plus haut.
On peut déjà retenir le fameux : accuracy=(precision+recall)/2.
Critères subjectifs
Le principal critère subjectif est sans doute celui permettant l’agrégation, c’est-à-dire de demander à des spécialistes du domaine d’évaluer qualitativement et des classer les logiciels à comparer.
Ce problème est certainement plus simple à traiter dans notre cas, car les expérimentateurs peuvent simplement dire quel système ils pensent être le meilleur. Mais ils peuvent aussi décomposer les parties (simplement en leur proposant l’ensemble de notre grille d’analyse) ou plus simplement signaler ce qu’ils pensent nécessaire d’améliorer. Il faut par contre soumettre les évaluateurs aux mêmes règles.
Échantillonnage
Les tests devront être échantillonnés principalement en fonction de deux critères :
Cela devrait permettre de mieux cerner, en fonction des types de requêtes et d’information, les qualités de chacun des formalismes.
On aura donc une structure de tests bidimensionnelles (indépendamment des évaluations de performances développées ci-dessus). Chacune de ces dimensions (structure/requête) est détaillée ci-dessous.
Structures
Les structures de représentation manipulées et leur représentation seront à définir.
Je propose de prendre comme base les structures engendrables par les systèmes d’analyse de langage naturel au minimum (YT). Le langage pivot peut être d’autant plus riche que comme il n’est pas question pour les systèmes d’en engendrer, le non-traitement de certaines constructions ne sera visible que dans ses performances.
Principes
L’un des premiers principes proposés était de séparer l’" ontologie " des individus (le pendant de support/graphes, classes/instances, tbox/abox). Mais il y plusieurs arguments contre cela:
La DTD admet donc des éléments individuels dans l'élément ontology. En ce qui concerne les éléments conceptuels dans l'élément contenu, on attendra.
Le langage de description rencontré dans les documents décrira des objets, leur appartenance à des classes et les valeurs de leurs attributs (une Abox typique de logique de description, sans contraintes de cardinalité) ainsi que des relations (avec classes, arguments et attributs). Le langage de description des " ontologies " comprendra la description des classes (et des classes de relations) dans une taxonomie avec la description des attributs (par leur type et restriction sur les types). En ce qui concerne les restrictions sur les types, on peut envisager de coller au plus près de l’application considérée et de ne pas forcer à tout prix des restrictions particulières. Les restrictions minimales seront (a) la spécification des classes auxquelles la valeur doit appartenir, (b) la spécification d’un ensemble de valeurs.
Format
Le format est spécifié dans la DTD escrire.
Voici le format du langage de document :
<<ICI METTRE UN EXEMPLE AVANT LA PROCHAINE RELEASE>>
Requêtes
Une hiérarchie de types de requêtes est proposée ici en fonction de ce qui peut être trouvé dans les langages de requêtes OntoBroker (JE), Search 97 (RD), ODMG (AN), Trek (YT) , XMLQL (OC). Les formalismes seront comparés en fonction de (1) leur couverture de l’ensemble de requêtes et (2) leur performance en fonction des critères sur chacun des types de requête.
Interprétation des requêtes
Un premier principe est que les requêtes, même si elles portent sur des entités quelconques, sont destinées à retourner des documents : ceux qui parlent de ces entités.
La force des systèmes à base de connaissance consiste à faire des inférences pour coller à la sémantique des langages ce qui n’est pas le cas par exemple de XQL car XML est structurel. Il est possible d’imaginer répondre aux requêtes en faisant des inférences uniquement en fonction du contenu d’un document ou en fonction du contenu de tous les documents connus. Dans cette éventualité, on retourne les groupes de documents permettant de répondre par l’affirmative à une requête. Dans l’ordre d’inclusion:
C doc0 A -> C, B-> C
D doc1, doc2, doc3 X -> Y / A -> X / B -> X
| doc2, doc7 X -> Y / A -> X / B -> X
| doc4, doc8, doc3 Z -> Y / A -> Z / B -> X
Mais, indexer les documents par le contenu n’est pas la même chose que construire une base de connaissance, par ailleurs dans le cas général la base obtenue ne sera ni consensuelle, ni consistante.
On prend donc la décision (éventuellement révisable après expérience) que les inférences ne sont que locales.
Langage de requêtes (textuel)
On peut reprendre le schéma classique introduit par SQL :
Par exemple :
SELECT K.name
FROM K:gene, Z:interaction, W:interaction
WHERE Z.target = K, W.target = K, Z.promoter = A, W.promoter = B
ORDER BY K.name
Retournera des réponses de la forme:
nom1 url1.1
url1.2
url1.3
nom2 url2.1
url2.2
où les
nom1,... sont les objets définis dans le SELECT et les url1,… ceux des documents permettant de répondre à la question (à noter que l’on pourrait imaginer SELECT FROM K:gene, R:interaction WHERE R.target=K). Les formats de requête et de retour seront communiquées au format XML (DTD qesc et resc) et manipulés suivant la procédure de la figure XX.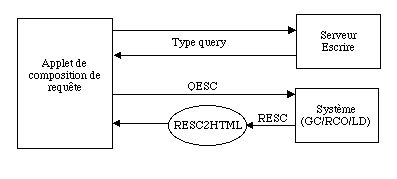
Figure XX. Acquisition et réponse à la requête.
On se penche donc plus longuement sur le champ WHERE.
where := cont (op cont)* // sélection
op := AND | OR // connecteurs
cont := NOT cont // contrainte
| quant comp / sur attribut
| in class / d’appartenance
| alike document /de proximité
CERTAINEMENT D’AUTRES ICI /…
quant := ALL | EXIST // quantificateur
comp := term pred term // comparaison
term := path | const // terme
path := attname (.atname)* // chemin
const := integer | string | regexp | set | list // valeur
pred := = | | ¾ | < |
Œ | … // prédicatChacun de ces aspects est examiné ci-dessous, les éléments entre [ et ] ne sont pas pris en compte actuellement dans la plate-forme, ceux entre [[ et ]] sont résolument éliminés.
Sélection sur les valeurs d'attributs
L’ensemble des documents ayant &i {val-i à caractéristique att-i}.
Comparateurs (prédicats)
La sélection des valeurs peut être raffiné par le mode de comparaison des valeurs. Il existe une hiérarchie de façon de définir val-i :
Chemins
La sélection des attributs peut être raffinée sur le mode d’Xpath/ODMG. Il existe une hiérarchie de façon de définir att-i :
Interprétation des requêtes (quantificateurs)
Soit une contrainte REQ telle que définie plus haut, elle peut s’interpréter avec diverses quantifications :
Il semble clair que
Cependant on a décidé de retenir les deux dernières interprétations marquées par un quantificateur explicite ALL ou EXIST.
ALL d.content IN class1
AND EXIST (x.length ¾ 2)
OR ALL d.authors.nationalité = "french")
Sélection sur les classes d'appartenance
L’ensemble des documents classés sous &i {classe-i} (on pourrait varier par " exactement attaché à ").
Proximité
L’ensemble des documents proches du document i
Sélection combinée
Elle peut aisément être réalisé en adjoignant au AND implicite des requêtes SQL, le OR et le NOT. Ces opérateurs seront disponibles dans la plate-forme.
Jointure
Stricto Sensu : l’ensemble des couples de documents joints par un sous ensemble de leurs caractéristiques (d1.a = d2.a).
Plus simple : une sélection avec des contraintes sur les caractéristiques d’un document en attribut (?).
Classement
Trouver la (les) classes d’un document.
Conclusions
Références
XML Query Requirements
W3C Working Draft 03 November 1999
http://www.w3.org/XML/Group/1999/11/xmlquery-req19991103
Concerto esprit project
Conceptual indexing, querying and retrieval of digital document
http://concerto.ccl.umist.ac.uk (surtout la partie evaluation), 1999
Annexe 1 : synthèse sur les langages de requêtes
On compare ici différents langages de requêtes afin d’élaborer les types de requêtes auxquelles le système devrait savoir répondre. Il faut cependant garder à l’esprit que des langages de type XQL/SQL sont des langages principalement structurels : si quelque chose peut être inféré (sur des bases sémantiques) d’un document XML, ces langages ne devraient pas pouvoir en tenir compte. Sans doute cela évoluera-t-il mais de manière détachée d’XML.
XML-QL et XQL WG
Il s’agit de deux langages de requêtes pour XML (le second en étant au stade des spécifications).
Des requêtes avec des chemins arbitrairement complexes dans la structure du document
Du pattern matching,
Des parties fixes et des parties variables
Des expressions régulières dans les balises
La construction de fragments de documents à partir des résultats de la requête.
À noter aussi un langage de requête, décrit dans le rapport http://www.ics.forth.gr/proj/isst/RDF/rdfquerying.pdf qui permet d'interroger du RDF ainsi que le schéma.
Les spécifications pour XQL WG sont :
On peut retenir pour ESCRIRE:
Tout d’abord, ces langages sont très liés à XML. Il n’est pas souhaitable de reproduire leur comportement là où ils seront bon. Il n’est par exemple pas très utile de reproduire les capacités de transformation visées en Extraction/Réduction/Retructuration/Transformation et Combinaison. Cependant, on introduira sans doute dans la partie générique au projet des possibilités d’assemblage de documents destinées.
On peut retenir :
Trouver les documents annotés par un objet O de classe C (ou une sous-classe de C) O:C
Exprimer des requêtes avec des chemins dans les objets (uniquement les chemins disponibles et non tout Xpath):
O1.s1.s2 = "XXX"
O2.s3.s4 = O3.s5.s6
Trouver la valeur d’une propriété d’un objet :
O1.s1 = ?X
?X est une variable, le fait d’utiliser une variable indique qu’on souhaite avoir la valeur en réponse à la requête, en plus de l’URL du document. Par exemple, je connais le titre je veux l’auteur.
La question d’utiliser des expressions régulières se pose (en faut-il où fais-t-on l’impasse sachant que ce n’est pas là qu’est la force des représentations de connaissance).
Une question plus importante est sans doute la possibilité d’ouvrir les résultats des requêtes à des requêtes XML quelconques (lorsque les résultats XQL seront disponibles). Il y a deux types d’ouverture :
On peut laisser le premier cas ouvert et voir si l’on est capable de le faire dans les temps du projet. Le second cas devra faire l’objet d’exemples plus détaillés et peut servir à définir un type de requête.
Ontobroker – Flogic
Select <var1>…<varn> such that <vari> :<typei>( featurei,j => vali,j ).
Il s’agit du Select de SQL dont les expressions sont plus que du relationnel puisqu’il s’agit de Prolog avec Feature-terms. [[Message pour Raphaël : regarder SQL, cela peut apporter ici]].
où vi,j est une variable où une constante.
On peut retenir pour ESCRIRE:
Sans doute le même type de schéma.
Dans notre cas, une constante pourra être un objet ou un nœud d’un graphe ou un graphe ; un type pourra être remplacé par une classe (ou une conjonction de classes).Le langage de contraintes sur les traits devra aussi être exprimé plus complètement (en F-logic il est défini par un prédicat).
ODMG
OQL est fortement basé sur SQL :
– select/from/where ;
select distinct struct ( name : x.name, pbp : (select y from x.parent where y.salaire > 10) )
from Person x
where x.age > 12
select p from Persons p, Flowers f where f.name = p.name
On peut retenir pour ESCRIRE:
Search 97 (Verity)
Search 97 permet au niveau des comparateurs de base:
Ces opérateurs de base sont assemblés à l’aide d’opérateurs booléens et de recherche de proximité textuelle avec recherche sur expression (adjacence), dans une phrase ou dans un paragraphe, distance paramétrable avec ordre imposé ou non,
Il permet aussi de la recherche par similarités (i.e. Query by Example),
On peut jouer sur l'analyse de la pertinence en indiquant au moteur les choix préférentiels pour la pondération des résultats (grâce à l'opérateur de cumul (ACCRUE)).
Pour calculer la pertinence, on utilise 4 paramètres :
Le résultat de la recherche est présenté trié par ordre décroissant de pertinence, paramétrable par l'utilisateur.
On peut retenir pour ESCRIRE:
La recherche par concepts (bien que les concepts utilisés seront définis bien différemment que dans Search 97 où ils se ramènent en fait aux résultats de requêtes prédéfinies). Les autres opérateurs étant plus spécifiquement textuels ou linguistiques, ils ne sont pas du domaine de compétence de l’ARC. Cependant, certains ont tout de même été retenus (joker, ordre).
L’opportunité d’introduire des opérateurs booléens et lesquels est à discuter mais semble intéressant. Les autres constructions d’assemblage étant typiquement textuels ne sont pas pertinents.
L’analyse de la pertinence est à étudier de plus près.
Trec – Text retrieval conference (YT)
Trec est une compétition de moteurs de recherche plein texte. Sa particularité est que les requêtes sont aussi exprimées de manière plein texte (balisé). Trek utilise les balises suivantes (qui contiennent du texte libre) :
Num : numéro
Title : titre
Desc : description de la réponse recherchée en lange naturelle
Narr : précision de la description (en général décrit un ensemble d’exemples pertinents et un ensemble d’exemples non pertinents).
http://trec.nist.gov/data/topics_eng/index.html
On peut retenir pour ESCRIRE:
Tout cela est vraiment trop textuel.
Annexe 2 : caractéristiques qualité (vues par Concerto/ISO 9126)
Voici les caractéristiques décrites dans le document Concerto cité plus haut. Il s’agit les deux premiers niveaux d’un arbre à développer en cas de besoin. En regard sont notés les critères plus adaptés à Escrire.
In more detail, the quality characteristics, and first level sub-characteristics, defined by ISO are as follows. Definitions may be found in ISO 9126-1nd, from which quotations in the following are taken. These characteristics are expected to be treated as normative, although it is recognised that there may be particular differences for particular evaluations. However, most variation is intended to occur at lower levels of sub-characteristics.
Functionality
"The capability of the software to provide functions which meet stated and implied needs when the software is used under specified conditions."
Suitability
Reliability
"The capability of the software to maintain its level of performance when used under specified conditions."
Usability
"The capability of the software to be understood, learned, used and liked by the user, when used under specified conditions."
Efficiency
"The capability of the software to provide the required performance, relative to the amount of resources used, under stated conditions."
Maintainability => inutile dans Escrire
"The capability of the software to be modified. Modifications may include corrections, improvements or adaptation of the software to changes in environment, and in requirements and functional specifications."
Portability => inutile dans Escrire
"The capability of the software to be transferred from one environment to another."
It is to be noted that, in terms of quality in use, characteristics are interdependent. That is, the assessment of quality in use may, for example, depend on an inter-relation of functionality, reliability and efficiency; or operability may depend on suitability, changeability, adaptability and installability.
Annexe 3 : canevas de fiche d’évaluation
L’idée est de se représenter comment les données des évaluations brutes pourront être visualisées mais aussi comment répartir les tests dans chaque jeu de test. Une table telle que celle-ci est à produire pour les évaluations objectives et une autre pour les évaluations subjectives.
|
Critère Requête |
Couverture (booléen) |
Rappel (%) |
Précision (%) |
Performance (complexité) |
Ordre (accord ?) |
Agrégation (?) |
|
Sélection |
||||||
|
- égalité |
||||||
|
- énum. |
||||||
|
- reg. exp. |
||||||
|
- interv. |
||||||
|
- class. |
||||||
|
- contr. |
||||||
|
Appart. |
||||||
|
Combin. |
||||||
|
Jointure |
||||||
|
Proximité |
||||||
|
Classif. |
||||||
|
Ordonnan. |
La performance devra s’apprécier en faisant varier par 10, 100, 1000 la taille des données (requête+base) et en évaluant la variation résultante.
Peut-être, l’ordre est-il à juger en fonction des critères d’ordonnancement (et il peut l’être sur plusieurs critères : rappel/précision des 5 premiers, critère d’accord à définir – p.ex. distance d’édition). Si cette évaluation est indépendante des types de requêtes (ce qui est vrai si les stratégies d’ordonancement ne sont pas définies de manière inductive sur les requêtes), on peut évaluer l’ordonancement dans un autre tableau :
|
Critère Ordre |
Rappel (%) |
Précision (%) |
Accord (e-distance) |
Agrégation (?) |
|
Satisfaction |
||||
|
Spécificité |