Rapport RDF-XML du 9/9/99
Plan
Introduction
RDF et XML
Le modèle RDF
Extensibilité de RDF
Conclusion
Introduction
XML (Extensible Markup Language) est une version simplifiée
du méta-langage SGML; il a la vocation de lier le pouvoir d'expression
de ce dernier à la simplicité d'utilisation de HTML. En pleine
explosion depuis quelques temps, il a donné naissance à de
nombreux langages spécialisés dans divers domaines (mathématique,
chimie, éducation, etc.).
RDF (Resource Description Framework) est un de ceux-là,
puisqu'il adopte une syntaxe basée sur XML, mais il n'est pas à
proprement parler une instance de XML. En effet, visant au départ
à décrire les ressources accessibles sur le web, il a été
conçu dans un souci d'extensibilité qui rend impossible sa
réduction à une DTD (Document Type Definition). (NB
: On pourrait construire une DTD de RDF, mais elle conduirait à
une syntaxe beaucoup plus lourde)
Le but de ce document est de comparer RDF à XML dans l'optique
de leur utilisation pour un système de raisonnement à partir
de cas. C'est l'objet de la première section. J'ai ensuite choisi
d'approfondir RDF, d'autre personnes ayant déjà étudié
la question de XML et présentant leurs travaux aujourd'hui. La deuxième
section présente donc succintemement le modèle RDF. Enfin,
la dernière section montre comment et dans quelles limites ce modèle
peut être étendu grâce à ses capacités
d'auto-description.
RDF contre XML ?
Modèles, documents et schémas
RDF et XML font tous deux appel aux mêmes notions, qu'on peut séparer
en deux groupes de deux, comme suit :
-
Document
-
Modèle
-
L'ensemble des informations, données ou connaissances, représentées
par le document.
Syntaxe
-
Comme son nom l'indique, l'aspect purement syntaxique du document. Un document
respectant la syntaxe XML est dit "bien formé".
-
Schéma
-
Modèle de schéma
-
Un ensemble de règles ajoutant des contraintes sur la structure
du document. Un document respectant ces contraintes est dit "valide" ;
on parle également d'une instance du schéma.
-
Syntaxe de schéma
-
Le schéma est lui aussi exprimé dans une certaine syntaxe.
Cette syntaxe peut être différente de celle des instances
(exemple : DTD) ou identique (exemples : XML-schema, RDF).
XML
La recommandation du W3C décrivant XML s'intéressait principalement
aux trois derniers points de cette liste (documents bien formés,
valides, et écriture de DTD). L'essor de ce langage, la prolifération
des analyseurs et les efforts de normalisation on conduit à l'apparition
d'un autre groupe de travail nommé "XML Information Set".
Ses travaux visent à mieux définir le modèle des
documents XML. Depuis, les autres groupes de travail s'y réfèrent
pour exprimer précisément leur influence sur le niveau Modèle.
C'est notamment le cas du groupe "XML Schema", présenté ci-après.
Il convient de noter que le modèle décrit dans "XML Information
Set" (parfois abrégé infoset) est intimement lié
à la structure syntaxique de XML. Par conséquent, un langage
de manipulation structurelle, comme XSLT (destiné originellement
à la mise en forme de documents XML), acquiert une réelle
puissance de traitement de l'information elle-même.
Le niveau Schéma a lui aussi été l'objet d'un nouveau
groupe de travail : "XML Schema". Ses travaux visent à augmenter
le pouvoir d'expression du niveau Modèle de schéma, en introduisant
une nouvelle Syntaxe de schéma. Cette nouvelle syntaxe a la
particularité d'être conforme à XML. Il existe donc
un schéma pour les Schémas-XML, exprimé aussi bien
dans une DTD que dans un Schéma-XML.
Les principaux apports par rapport aux DTD sont l'héritage au
niveau des éléments, et les types de données au niveau
des chaînes de caractères (éléments ou attributs).
RDF
Le groupe de travail RDF quant à lui, à préféré
séparer en deux documents la définition de ce langage : "RDF
Model and Syntax" (recommandation) et "RDF Schemas" (proposition de recommandation),
qui se rapportent aux niveaux correspondant dans la liste ci-dessus.
Le modèle RDF, décrit dans la deuxième
section de ce document, n'a strictement rien à voir avec le
modèle décrit par "XML Information Set". Ainsi, même
si la syntaxe de RDF est basée sur XML, un analyseur RDF ne fournit-il
pas du tout les mêmes informations que l'analyseur XML sur lequel
il est basé.
Cette différence au niveau Modèle se propage tout naturellement
au niveau Schéma. La validité au sens de RDF n'est
pas la validité au sens de XML (ceci est d'autant plus vrai que
la syntaxe proposée pour RDF n'admet pas de DTD, et qu'un document
RDF ne peut donc être XML-valide). Les schémas RDF s'expriment
à l'aide de RDF lui-même, et il existe donc un schéma
pour les schémas RDF.
Une autre conséquence de ce modèle différent de
infoset,
c'est qu'il n'existe pas de bijection entre le niveau Syntaxe et le niveau
Modèle. Ainsi, il existe plusieurs écritures pour le même
modèle, et il existe des écritures bien formées au
sens de XML n'ayant aucun sens dans le modèle RDF. On perd ainsi
un gros avantage de XML : celui de pouvoir manipuler l'information simplement
en manipulant le document.
En contrepartie, RDF permet d'exprimer des faits qui ne sont pas exprimables
trivialement avec infoset. Ce sera l'objet de la deuxième
section.
Conclusion
C'est donc la structure des informations fournies par l'analyseur qui différencie
principalement XML et RDF. Pour XML, c'est une structure simple, très
liée à la syntaxe, avec les avantages que cela comporte.
Pour RDF, une structure un peu plus riche, inspirée du domaine de
la représentation des connaissances.
Mais cela ne fait pas de RDF plus que XML un langage de représentation
des connaissances. Pour l'un comme pour l'autre, une adaptation et un enrichissement
du modèle, et donc de l'analyseur, sont nécessaires.
Le choix de l'un ou de l'autre dépend donc du type de représentations
des connaissances visé : s'il se projette de façon satisfaisante
sur le modèle RDF, l'analyseur RDF aura l'avantage de fournir un
certain nombre de mécanismes en standard que ne fournit pas l'analyseur
XML (fig.1). Mais dans le cas contraire, mieux vaut adapter directement
ce modèle au dessus de l'analyseur XML plutôt que de s'encombrer
d'une couche supplémentaire (fig.2).
______________________________
/ ____________________ \ _____________________
|/ __________ \ | <-fig.1 / ___________ \
||/parser XML\ valider| valider| |/valider XML\ valider|
||\__________/ RDF | RDF++ | fig.2-> |\___________/ XML++ |
|\____________________/ | \_____________________/
\______________________________/
Les deux sections qui suivent présentent donc le modèle RDF
et son extensibilité. Les travaux de Jérôme Euzenat
devraient fournir l'équivalent sur XML/DTD. Il reste à considérer
XML-Schema, pour lequel il n'existe pas encore d'analyseur, mais qui devrait
à terme présenter une alternative intermédiaire entre
la simplicité de XML et les fonctions plus évoluées
de RDF (héritage, littéraux typés).
Le modèle RDF
Graphe direct étiqueté
Le modèle RDF a une structure de graphe dont les arcs sont munis
d'un sens et d'une étiquette. Les noeuds du graphes sont des ressources
(c'est à dire toute entité pouvant être désignée
par une URI) ou des littéraux (i.e. des chaînes de
caractères). Les étiquettes des arcs sont des ressources
particulières appelées Propriétés, définie
dans un schéma (cf. plus loin la définition des schémas
en RDF).
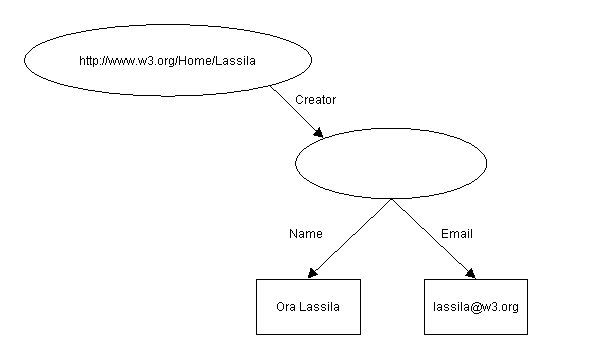
Dans l'exemple ci-dessus, la ressource http://www.w3.org/Home/Lassila
a pour créateur une ressource anonyme, ayant elle même pour
nom le littéral "Ora Lassila" et pour adresse électronique
le littéral "lassila@w3.org".
Description
Comme son nom l'indique, le but de RDF est de décrire des ressources.
L'entité centrale du langage est donc la description. Une description
peut qualifier ou définir une ressource, comme dans l'exemple ci-dessous,
qui correspond à la figure précédente.
<Description about="http://www.w3.org/Home/Lassila">
<Creator>
<Description>
<Name>Ora Lassila</Name>
<Email>lassila@w3.org</Email>
</Description>
</Creator>
</Decsription>
A l'aide de l'attribut about, la description extérieure
qualifie
la ressource en question. La description encapsulée ne contient
aucun attribut ; elle définit une ressource anonyme. Cette
ressource pourrait être nommée avec l'attribut
ID.
Le langage propose également d'autres attributs permettant de
factoriser une description sur un ensemble de ressources : aboutEach
permet de qualifier tous les éléments d'un conteneur (cf.
ci-dessous), et aboutEachPrefix permet de qualifier toutes les
ressources dont l'URI commence par le préfixe donné.
Conteneurs et énoncés
Le modèle RDF propose également une sémantique pour
un certain nombre de structures particulières. Les premières
sont les conteneurs : Bag, représentant un ensemble d'éléments
sans considération pour leur ordre, Seq représentant
une séquence ordonnée d'élément, et Alt
représentant un élément à choisir parmi un
ensemble .
Autre structure particulière : les énoncés, ou
Statement,
qui servent à réifier un arc du graphe en une ressource,
que l'on peut décrire à son tour.
Schémas RDF
Le modèle de schémas RDF ajoute le concept de Classe, et
les notions de spécialisation (des classes et des propriétés),
de typage (en généralisant les structures proposées
pour les conteneurs et les énoncés) et de contraintes sur
les propriétés : domaine (classe autorisée pour la
ressource de départ de l'arc) et portée (classe autorisée
pour la ressource d'arrivée de l'arc). Ces notions sont associées
à des ressources, définies dans un document RDF de référence,
permettant d'utiliser RDF lui même comme syntaxe de schémas.
Voici les principales ressources utiles à la définition
des schémas (les noms des classes commencent par une majuscule,
les nom des propriétés commencent par une minuscule) :
Resource
La classe la plus générale de la hiérarchie d'héritage.
Class
La classe de toutes les classes.
Property
La classes de toutes les propriétés (étiquettes valides
pour les arcs).
Container
La classe de tous les containers. Bag, Seq et Alt
(qui sont aussi des classes) en héritent.
Statement
La classe de toutes les réifications d'arc (généralisation
de la structure d'énoncé).
type
portée : Class ; exprime l'appartenance d'une ressource
à une classe.
subClassOf
domaine et portée : Class ; exprime la relation d'héritage
entre deux classes.
subPropertyOf
domaine et portée : Property ; exprime la relation de spécialisation
entre deux propriétés.
domain
domaine : Property, portée : Class ; exprime le
domaine d'une propriété.
range
domaine : Property, portée : Class ; exprime la
portée d'une propriété.
Voici un exemple de schéma utilisant la syntaxe abrégée
: le nom d'une classe est utilisée à la place du mot Description.
Ceci ajoute implicitement un arc type pointant vers cette classe.
Notons aussi que pour être parfaitement correct, cet exemple devrait
utiliser les espaces de nommage (namespaces).
<Class ID="Vehicle"/>
<Class ID="Car">
<subClassOf rdf:resource="#Vehicle"/>
</Class>
<Class ID="4x4">
<subClassOf resource="#Car"/>
</Class>
<Property ID="authorizedDriver">
<domain resource="#Car"/>
</Property>
<Property ID="owner">
<subPropertyOf resource="#authorizedDriver"/>
</Property>
Enfin, voici une portion de RDF utilisant le schéma précédent.
<4x4 ID="myCar">
<owner>Pierre-Antoine CHAMPIN</owner>
<authorizedDriver>Marie-Pierre, ma femme</authorizedDriver>
<authorizedDriver>Victor, mon chauffeur</authorizedDriver>
</4x4>
Un valideur RDF (i.e. un analyseur utilisant les schémas)
devra inférer un certain nombre de choses de la description précédente
:
-
puisque myCar est de type 4x4, il est aussi de type Car
et Vehicle (par la relation subClassOf).
-
puisque je suis propriétaire de myCar, j'en suis aussi
un conducteur autorisé (par la relation subPropertyOf).
Complexité
Il est évident qu'un tel modèle, capable de s'exprimer à
propos de ses éléments constitutifs (créer une sous-classe
de Class, une sous-propriété de subPropertyOf,
etc.),
risque d'être entraîné dans des mises en abîmes,
potentiellement infinies. Pour être utilisables, les valideurs RDF
doivent limiter ce pouvoir d'expression. On peut déplorer que les
spécifications de RDF ne posent pas une fois pour toutes de telles
limitations ; d'un autre coté, cette politique est moins contraignante,
laissant chaque développeur de valideur libre de fixer ces limitations
en fonction du type de l'application cible, et de les gérer comme
il le souhaite (messages d'avertissement ou d'erreur, contraintes de validité
supplémentaires).
Extensibilité de RDF
Comme il a été dit en conclusion de la première
section, RDF nécessite d'être amélioré pour
faire de lui un véritable langage de représentation de connaissances.
Le problème d'une telle amélioration réside dans la
compatibilité avec les spécifications du langage, et les
complexité par rapport à l'analyseur standard. Je vais présenter
ici deux lacunes de RDF qu'on peut envisager de combler, avec leurs influences
sur ces facteurs.
Spécialisation induite
Il existe deux types de spécialisation en RDF : spécialisation
de classes (subClassOf) et spécialisation de propriétés
(subPropertyOf). Ils permettent à un valideur RDF de faire
trois types d'inférences, illustrés dans les exemples suivants
:
-
Inférence sur le type
-
Si Médor a le type Chien, et si Chien est une sous-classe de Animal,
alors Médor a aussi le type Animal.
-
Inférence sur les arcs
-
Si Jean a pour mère Jeanne, et si "mère" est une sous-propriété
de "parent", alors Jean a pour parent Jeanne.
-
Inférence sur les réifications d'arc
-
Si un énoncé a pour prédicat "mère", et si
"mère" est une sous-propriété de "parent", alors cet
énoncé a aussi pour prédicat "parent".
Le troisième type d'inférence est la traduction du deuxième
à travers le processus de réification. Pourtant, il a tendance
à être oublié dans les implémentations de RDF.
Il a une structure parfaitement isomorphe à celle du premier type
d'inférence, qui peut se généraliser en :
S'il existe un arc (R1, prop1, R2) et un arc (R2, prop2, R3)
avec prop2 ayant une structure de hiérarchie
et prop1 et prop2 entretenant un rapport particulier
alors on peut inférer un arc (R1, prop1, R3)
Par "structure de hiérarchie", on se limitera ici à la contrainte
imposée à subClassOf et subPropertyOf,
à savoir que les arcs correspondant ne doivent pas former de cycle,
et que la relation est considérée comme transitive.
Le "rapport particulier" qui existe entre prop1 et prop2 sera baptisé
"spécialisation induite" : du fait de la hiérarchie prop2,
R2 spécialise R3 en tant que valeur pour prop1. Si on admet que
toute hiérarchie induit une spécialisation sur elle même,
on peut supprimer l'hypothèse de transitivité, car elle découle
de la règle ci-dessus.
Une hiérarchie peut induire une spécialisation sur plusieurs
propriétés, et sa relation inverse peut également
induire une spécialisation, comme on le voit dans l'exemple suivant.
En revanche, je ne vois pas de cas où une même propriété
pourrait avoir une spécialisation induite par plusieurs hiérarchies...
Exemple :
la hiérarchie "contenuPar" s'applique aux lieux.
Part-Dieu contenuPar Lyon contenuPar France
elle induit une spécialisation sur les propriétés
"né" et "habite"
si Jean est né à Lyon, il est né en France
si Jean habite Lyon, il habite la France
sa relation inverse induit une spécialisation sur la propriété
"connaît comme sa poche"
si Jean connaît Lyon, il connaît la Part-Dieu
J'ai écrit un schéma RDF définissant
les ressources Hierarchy et inducedSpecialization permettant
d'exprimer qu'une propriété est une hiérarchie, et
qu'elle induit une spécialisation sur une autre propriété.
Enfin, j'ai adapté un analyseur RDF pour qu'il exploite ces informations
afin d'inférer plus d'informations qu'un analyseur standard.
Cette extension de RDF (appelons la X) remet en cause la validité
des documents : un document RDF-valide peut être X-invalide s'il
ne respecte pas les contraintes, non exprimables en RDF, liées à
l'utilisation du schéma supplémentaire (pas de cycles dans
les hiérarchies, une seule spécialisation induite par propriété...).
En revanche, elle ne remet pas en cause l'invalidité : aucun document
RDF-invalide ne peut être X-valide. Ainsi, tout document X-valide
est portable : il peut être lu tel quel par un valideur RDF standard,
même si ce dernier en tirera moins d'informations qu'un valideur
X.
En terme de complexité, le valideur X est identique à
un valideur RDF standard puisqu'il ne fait que généraliser
l'utilisation d'un mécanisme d'inférence déjà
nécessaire dans tout valideur RDF.
Description de classes en intension
Les classes RDF correspondent grossièrement aux concepts primitifs
des logiques de description : elles sont décrites en extension dans
la mesure ou seules les ressources ayant un arc type explicite
(vers cette classe ou une de ses sous-classes) peuvent prétendre
y appartenir.
On peut leur opposer les classes décrites en intension, cette
fois comparables aux concepts définis des logiques de description,
qui admettraient comme instance toute ressource vérifiant un certain
nombre de condition.
On peut donc envisager de créer une sous-classe de Class,
nommée Template (gabarit). Les gabarits admettraient une
description des conditions à remplir par leurs instances. Une extension
Y au valideur RDF serait alors munie des mécanismes d'inférences
nécessaires pour déduire l'appartenance où non d'une
ressource à un gabarit. Contrairement à l'extension précédente,
celle-ci risque d'augmenter nettement la complexité de l'analyseur
- en fonction du pouvoir d'expression donné sur la définition
du gabarit.
D'autre part, cette extension remettrait en cause à la fois la
validité et l'invalidité : elle pourrait considérer
comme valide des documents RDF-invalides puisqu'elle pourrait inférer
des arcs type nécessaires à la vérification
de contraintes (domaine ou portée, par exemple). Les documents Y-valides
ne seraient donc pas portables. La communication avec d'autres valideurs
RDF devrait dans ce cas passer par l'explicitation de certains arcs inférés.
Conclusion
Malgré la simplicité de son modèle, RDF paraît
proposer des mécanismes intéressant pour la représentation
de connaissances. Il s'est avéré possible d'étendre
le pouvoir d'expression de ce langage, mais il convient de bien identifier
les conséquences de chaque extension sur la portabilité du
langage étendu, ainsi que sur l'efficacité du nouveau valideur.
Une première extension a déjà été réalisée,
conservant la portabilité et la complexité du modèle
original.